
Data annotation is like teaching AI models to understand the world by giving them carefully labeled examples. Imagine teaching a child to recognize different animals by showing them pictures and saying "this is a cat" or "this is a dog." That's essentially what data annotation does for machines.
In simple terms, data annotation is the process of adding labels, tags, or notes to different types of information – like pictures, videos, text, or audio recordings. These labels help computers learn to recognize patterns and make sense of information, much like how humans learn from labeled examples.
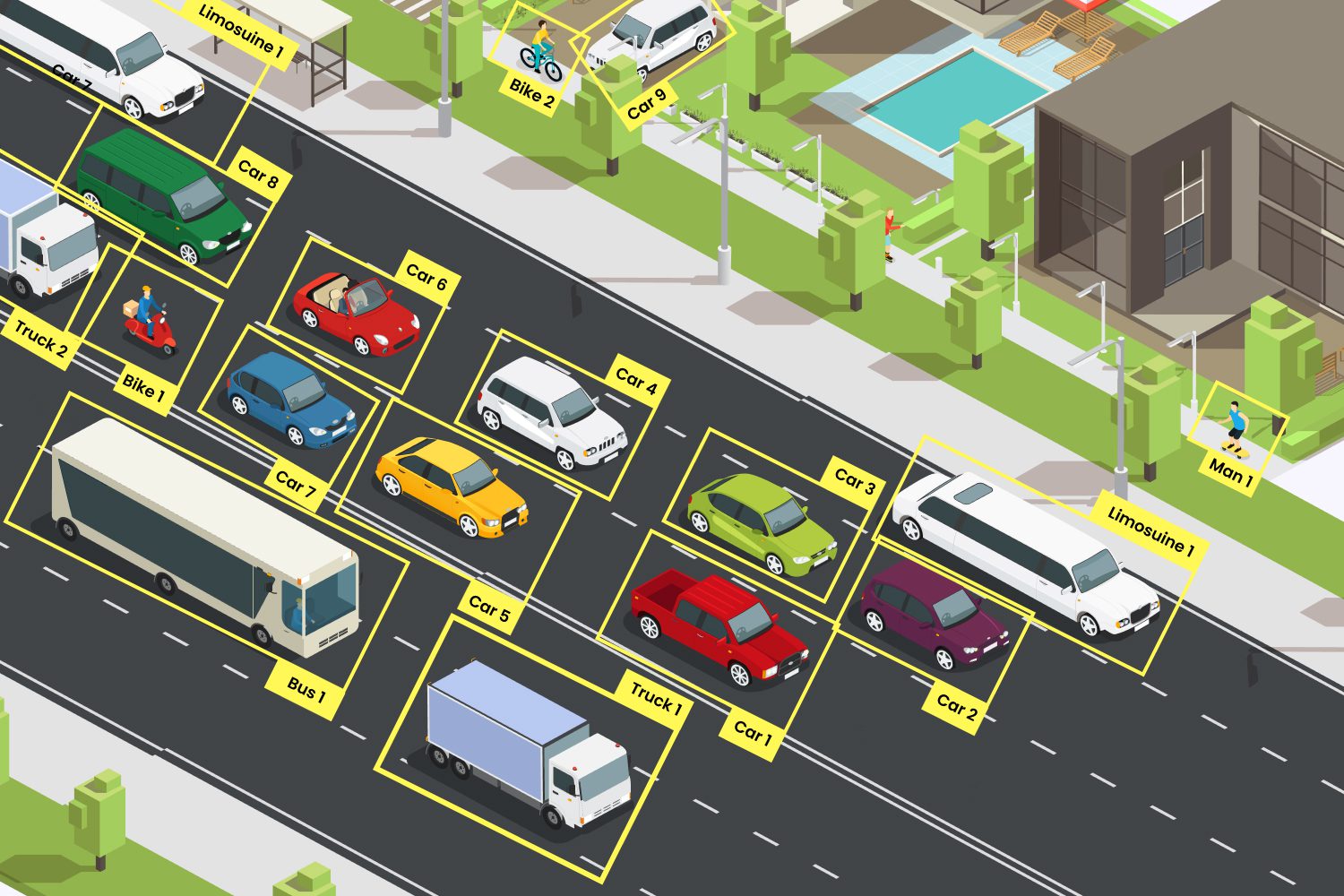
For instance, when building a self-driving car system, people carefully mark important things in thousands of street photos – like other cars, pedestrians, traffic lights, and road signs. This helps the car's computer system learn what to look for when it's actually on the road.
The data annotation and labeling market is valued at USD 2.2 billion in 2024 and is expected to experience robust growth, with a projected compound annual growth rate (CAGR) of 27.4% from 2024 to 2030. This surge is driven by the rising need for high-quality training data to support machine learning and AI advancements.
In the next sections, we’ll look at what data annotation is, it’s types, challenges, and advanced techniques used in data annotation.
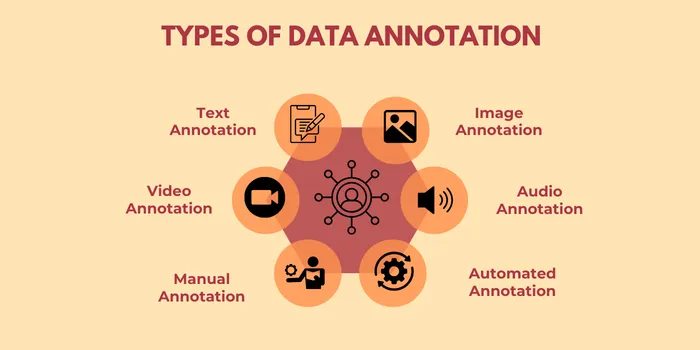
Data annotation encompasses various types tailored to specific AI applications.
It involves labeling textual data for tasks such as sentiment analysis, intent detection, and named entity recognition. This process aids natural language processing (NLP) models in understanding human language by tagging entities like names, dates, and locations or identifying emotions and contextual meanings in sentences.
Image annotation marks objects, regions, or attributes within images, often using techniques like bounding boxes, polygons, and semantic segmentation. It is widely used in applications like facial recognition, medical imaging, and autonomous driving, enabling models to identify and categorize objects such as pedestrians, vehicles, or tumors.
Video annotation extends image annotation by labeling objects frame-by-frame in video sequences. It includes tracking movements, recognizing actions, or tagging events, critical for fields like surveillance, sports analytics, and robotics. Advanced techniques, such as object tracking and temporal tagging, ensure models can interpret dynamic environments.
It involves tagging audio data for speech recognition, sound classification, or language translation. Tasks include transcribing spoken words, identifying speakers, and categorizing non-speech sounds like alarms or music. This type is essential for voice assistants, call center analytics, and environmental monitoring.
It involves human effort in labeling data. Annotators use specialized tools to tag elements relevant to the AI model's objective. This approach is labor-intensive but offers unmatched accuracy, as humans can understand complex contexts, emotions, and nuances that algorithms cannot yet comprehend.
It utilizes AI to label data at scale. Algorithms identify patterns and tag data based on predefined rules. While faster than manual methods, automation often requires human oversight to validate outputs and correct errors, especially in datasets with subtle complexities or ambiguities.
Specialized tools play a pivotal role in optimizing data annotation by offering intuitive interfaces and features tailored to various data types.
These tools simplify complex annotation tasks, such as drawing bounding boxes around objects in images, performing semantic segmentation to label pixels, or transcribing speech into text. With their user-friendly designs, they enable annotators to focus on accuracy and efficiency, reducing manual effort and error rates.
Advanced annotation platforms integrate AI-powered features to assist human annotators. For instance, auto-labeling functions leverage pre-trained models to make initial predictions, which annotators can then review and refine. This hybrid approach significantly accelerates workflows, particularly in large-scale projects. Tools also support features like version control, enabling teams to track changes and ensure consistency across multiple annotators.
The choice of an annotation tool depends on the dataset's type, size, and complexity. For example, tools designed for image annotation may include 3D labeling for autonomous vehicle datasets, while those for text annotation might offer sentiment tagging or entity recognition. Scalability is another crucial factor; cloud-based platforms facilitate collaboration and handle extensive datasets effectively.

Data annotation faces challenges like scalability, subjectivity, and cost. Let’s explore them in detail below:
Ethics in data annotation involve respecting privacy, avoiding bias, and ensuring fair labor practices for annotators. Datasets must be anonymized to protect personal information, and diverse perspectives should inform annotations to prevent reinforcing stereotypes or systemic inequities in AI outcomes.
Active learning enhances annotation efficiency by focusing on uncertain or ambiguous data points. Models flag instances where predictions are unclear, guiding annotators to label these cases. This iterative approach minimizes redundant effort, accelerating dataset preparation for training.
Let’s explore some advanced concepts that define the data annotation process.
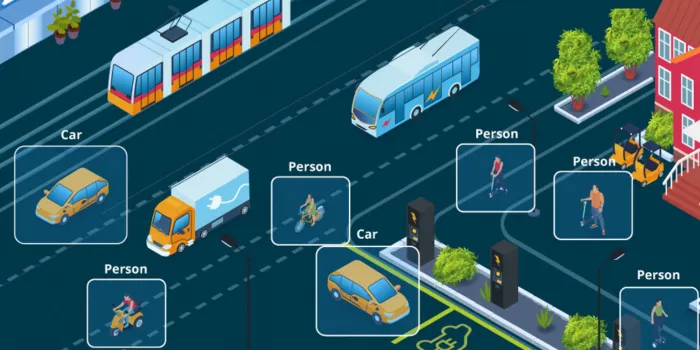
Semantic segmentation assigns each pixel in an image to a specific class, creating detailed maps that allow AI to interpret environments with precision. This technique is vital for applications like robotics and autonomous driving, where systems must accurately identify objects such as pedestrians, vehicles, or traffic signals in complex and dynamic scenes. By segmenting every pixel, models gain a richer understanding of spatial relationships, improving decision-making and navigation capabilities.
Additionally, semantic segmentation enhances applications beyond transportation. In healthcare, it enables precise labeling of medical images, aiding in diagnosing diseases. For example, pixel-level segmentation of MRI scans helps doctors identify tumors or anomalies. As datasets grow in size and complexity, tools supporting semantic segmentation ensure efficient annotation, allowing AI systems to excel in high-stakes environments.
Annotations for NLP tasks focus on tagging elements like parts of speech, named entities, and sentiment, providing essential data for AI to understand language. For instance, annotators label proper nouns as names or locations, while tagging sentence tones helps models determine user emotions in sentiment analysis. Comprehensive annotations ensure the AI captures the nuances of human language.
These annotations are crucial for conversational agents and chatbots, allowing them to respond contextually and appropriately. For example, labeling syntactic structures helps models identify grammatical relationships, improving sentence generation. By integrating these detailed annotations, NLP models can perform tasks like translation, summarization, and sentiment detection with increased accuracy and fluency.
Ambiguity in data presents challenges in annotations, especially when sentiments are unclear or objects are partially visible in images. Such cases require annotators to make subjective decisions, which can introduce inconsistencies. Addressing ambiguity involves robust annotator training and offering contextual data, ensuring better alignment with project goals.
Expert reviews are also critical for ambiguous cases. Cross-checking annotations among skilled professionals reduces errors and improves dataset reliability. These efforts create a foundation for more consistent and interpretable models, especially in sensitive applications like legal text analysis or medical diagnostics.
Transfer learning enables pre-trained models to adapt to new tasks with minimal data. Annotated datasets are critical in fine-tuning these models, allowing them to generalize effectively across different domains. This reduces the need for extensive data collection while maintaining high performance.
For instance, a model trained on general image recognition tasks can be fine-tuned to detect specific objects like medical instruments by annotating relevant images. This efficiency makes transfer learning especially valuable in specialized fields where obtaining large datasets is challenging, such as rare disease research or niche industries.
Synthetic data, generated through simulations or algorithms, complements real-world datasets by addressing gaps in data diversity. Annotating synthetic data allows models to train on scenarios that are rare or difficult to capture, such as extreme weather conditions or unusual medical cases.
This approach is particularly useful for testing AI robustness. By creating diverse datasets with edge cases, models can be trained to handle unforeseen scenarios. For example, autonomous vehicle systems use synthetic data to simulate complex traffic situations, ensuring safety and reliability in real-world applications.
AI-assisted annotation tools predict labels for raw data, enabling annotators to review and refine outputs. This hybrid approach significantly accelerates the annotation process, especially for vast datasets in industries like e-commerce or social media, where speed is crucial.
By reducing manual effort, AI-assisted tools improve efficiency while maintaining accuracy. Annotators focus on correcting errors or refining predictions, ensuring high-quality data. This scalable approach is essential for meeting the growing demands of modern AI applications.
Domain adaptation refines annotations to fit specific contexts, ensuring models remain relevant across different use cases. For example, sentiment analysis models trained on English text may require adjustments to account for cultural nuances when applied to another language.
This process also involves adapting labels to industry-specific terminologies. In finance, for instance, annotators may need to tag transaction types differently based on regional regulatory requirements. Domain adaptation enhances model applicability, ensuring consistency and accuracy across diverse scenarios.
In reinforcement learning, annotations define rewards and penalties, guiding agents to learn optimal behaviors. For instance, annotators label successful outcomes in a game or a robot’s navigation path, enabling the system to understand its objectives.
These annotations are integral to creating structured environments where agents can learn efficiently. By tagging desired actions or scenarios, reinforcement learning models become more adept at decision-making, improving their performance in dynamic and unpredictable tasks.

Annotations play a key role in explainable AI by providing traceable and interpretable labels. This transparency helps stakeholders understand how models reach decisions, fostering trust in critical applications like healthcare and finance.
For example, detailed annotations allow models to justify their predictions, such as identifying the features that led to a diagnosis. By linking outcomes to labeled data, explainable AI ensures accountability and builds confidence among users and regulators.
Human-in-the-loop systems integrate annotators throughout AI development, ensuring models remain accurate and adaptable. Annotators intervene to correct errors or guide learning, especially in complex or evolving datasets.
This collaborative approach bridges the gap between machine efficiency and human judgment. It is particularly effective in dynamic environments like fraud detection, where real-time feedback from annotators helps models adapt to new patterns, maintaining reliability over time.
Data annotation is the cornerstone of artificial intelligence, providing the structured, labeled datasets essential for training accurate and reliable models. From text and image annotation to advanced techniques like semantic segmentation and domain adaptation, the process ensures AI systems can navigate diverse and complex applications.
Handling challenges like ambiguity, scaling with AI-assisted tools, and leveraging synthetic data exemplifies the sophistication required in modern annotation practices. These efforts not only elevate model performance but also foster trust, transparency, and adaptability in AI technologies.
LexiConn, the best content writing agency in Mumbai, offers a team of expert data annotators equipped to deliver meticulous, high-quality annotations across diverse industries. Whether your project involves NLP, computer vision, or reinforcement learning, our team ensures your datasets are tailored for success, enabling your AI systems to perform at their best.
Partner with LexiConn to elevate your AI projects with reliable, scalable, and expertly annotated data. Visit our website or book a free consultation.



I have read and accept the Privacy Policy
Read More
{kind=link}
{kind=link}
{kind=link}