
Artificial intelligence (AI) has the potential to revolutionize industries and transform how we live and work. However, for AI models to function effectively, nothing is more fundamental than quality data, regardless of how advanced they may be.
With data annotation, AI models can learn from raw, unstructured data and improve their performance over time, enabling them to succeed.
In this blog, we will explore how data annotation helps AI models learn and improve, how it contributes to various AI applications like image recognition, natural language processing (NLP), and machine learning (ML), and offer a deeper understanding of its significance.
Before diving into the specifics of how data annotation aids AI models, it’s essential to understand what data annotation actually is.
Data annotation is the process of labeling or tagging raw data (whether it's images, text, audio, or video) so that AI and machine learning models can interpret it correctly. Raw data by itself is not sufficient for training an AI model. In fact, AI systems can often struggle to make decisions without this structured, labeled data.
Data annotation acts as a bridge, transforming unstructured data into a format that machine learning algorithms can understand and use to recognize patterns, make predictions, and ultimately make smarter decisions.
For instance, imagine you’re building a model to recognize different animals in pictures. To do this, you'd need to annotate each image with labels, such as "dog," "cat," "bird," or any other relevant categories. These labeled images serve as the training data that the model will use to identify animals in new, unseen pictures. Without these annotations, the AI model would have no idea how to classify objects in images, no matter how advanced the algorithm is.
As per The Economic Times, gig workers in India train AI models through microtasks. India is becoming a key data annotation hub with a potential 82,200 crore INR global market and a workforce of over a million by 2028.
Data annotation is critical for improving the learning process of AI models, especially for supervised machine learning tasks. Supervised learning is a type of machine learning that relies on labeled datasets to train algorithms to identify patterns and make predictions.
Without the labeled data, AI models wouldn't have the "training wheels" they need to understand and process information accurately.
The role of data annotation in improving AI models can be seen across various AI applications, including:
NLP applications, such as machine translation (automatically converting text from one language to another), rely heavily on text annotation. This could involve tagging parts of speech, identifying entities like names or locations, and marking sentiment within sentences.
At LexiConn, we can assist in all of the above-mentioned applications through precise data annotation and labeling, guided by data scientists, subject matter experts, and experienced data annotators.

The process of data annotation varies based on the type of data being used. There are several different techniques, each of which is tailored to the type of data it needs to process. Below are some of the most common types of data annotation techniques:
In computer vision, image annotation refers to the process of labeling various objects in images. This is particularly useful in fields like autonomous vehicles, medical imaging, and surveillance.
Some of the image annotation techniques include:
For example, in retail analytics, bounding boxes can be applied to label and track products on shelves, ensuring accurate stock management and enabling AI-powered systems to monitor inventory levels in real time.
2. Video Annotation
Video annotation is crucial for training AI models used in dynamic environments where objects or people are constantly in motion. In video annotation, each frame of the video may need to be labeled to identify actions or objects.
For example, in sports analysis, action recognition through video annotation can be employed to label actions like "kicking," "dribbling," or "scoring." This allows AI models to analyze player performance, optimize strategies, and deliver insights into game patterns.
3. Text Annotation
Text annotation is a foundational technique for Natural Language Processing (NLP). It involves adding labels to text data so that AI models can understand the underlying meaning, context, and relationships within the text.
Common types of text annotation include:
For example, in a customer feedback analysis application, annotating text with sentiment labels enables an AI model to classify feedback as positive or negative, helping companies assess customer satisfaction.
Audio annotation involves labeling and tagging elements of audio data to enable AI systems to recognize sounds, speech, or music.
In AI applications like virtual assistants or transcription services, audio annotation is often necessary to help the system understand speech and convert it into useful text.
The process of data annotation directly impacts the performance of AI models, particularly in machine learning tasks where labeled data is necessary. Here’s how high-quality data annotation helps AI models learn and improve:
1. Enhancing Accuracy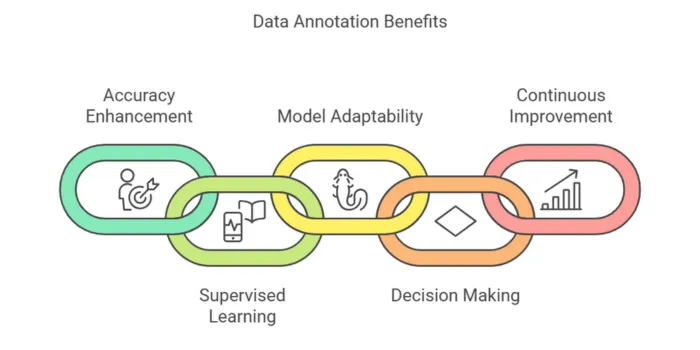
Accurate annotations ensure that the AI model receives precise information to learn from. For instance, if an image of a street scene is incorrectly labeled, the AI model will learn the wrong patterns, leading to poor performance when deployed in real-world applications like autonomous courier service. Proper annotation provides the model with clear, reliable training data, which is essential for producing accurate results.
Data annotation plays a key role in supervised machine learning by providing the necessary labels that help the model understand the relationships between input data (like an image or text) and the desired output (like object labels or sentiment). This allows the AI to generalize its learning to new, unseen data. Supervised learning enables organizations to tackle various real-world challenges on a large scale, such as filtering spam emails into a separate folder in your inbox.
With high-quality annotated data, AI models become more adaptable and flexible. By training on diverse datasets with accurate annotations, AI systems can better handle a variety of real-world scenarios. For example, an AI model trained to recognize different types of plants based on labeled images can adapt to identify new species more easily if exposed to a variety of plant images during training.
AI models rely on annotated data to make decisions based on learned patterns. For instance, in healthcare, an AI trained on accurately annotated medical images can help doctors detect diseases like cancer at earlier stages. The accuracy of the data directly influences the model’s ability to make reliable decisions, improving both efficiency and outcomes.
Data annotation is not a one-time task. As AI models are exposed to more data and new challenges, they need continuous updates in the form of fresh, well-annotated datasets. This iterative process helps improve the model’s accuracy, adaptability, and decision-making capabilities over time. By regularly refreshing and adding new data, businesses can ensure their AI models stay relevant and effective.
According to a GV research report, the India data annotation tools market generated a revenue of 809 crore INR in 2023 and is expected to reach 4,924 crore INR by 2030.
Common Challenges in Data Annotation
While data annotation is crucial for AI development, it does come with its own set of challenges:

The role of data annotation will continue to evolve as AI and machine learning technologies progress. In the future, we can expect:
Data annotation is at the heart of training and improving AI models. Whether it's image recognition, NLP, or speech processing, high-quality annotated data is what empowers AI to learn and make decisions.
By understanding its role, businesses can better leverage AI to improve their products, services, and overall operations. Despite the challenges, the future of data annotation is bright, with innovations set to make the process more efficient, accurate, and scalable.
Through well-executed data annotation practices, we can continue to unlock the potential of AI and drive further advancements in this transformative field.
At LexiConn, we have a proven track record of navigating these challenges. For instance, we partnered with one of India’s top OTT platforms to tag over 1.4 lakh videos, significantly enhancing their content recommendation engine.
If you need a reliable data labeling partner, connect with LexiConn today. Our experienced team can provide tailored data labeling solutions, even for the most complex projects.



I have read and accept the Privacy Policy
Read More