
Do you know what’s worse than running out of gin? AI models running on junk data.
Here’s the thing: data annotation for AI is like therapy for machines. You sit them down, label their messy thoughts—sorry, data—and suddenly they start making sense. Image and video annotation? That’s the bit where you teach your AI to look at a cat and say, “Yes, that’s a cat,” and not, “Maybe it’s a slightly angry toaster.”
AI and machine learning are skyrocketing. I’m talking about “$62.5 billion-to-$1.4 trillion-by-2029” kind of skyrocketing. Everyone, from healthcare to logistics, is obsessed. But here’s the kicker: without accurate data annotation training, those AI systems? Absolutely useless.
Why? Because AI doesn’t just know things. It needs you to tell it things—over and over—until it can sort itself out and function like an adult. That’s why data annotation is important. It takes chaotic, unstructured data and transforms it into labeled organized brilliance.
Now, let’s talk about real stakes. According to a survey, 94% of AI professionals said “data quality” makes or breaks their models. No good data? No good AI. Full stop. And honestly, the world doesn’t need another AI mistaking a squirrel for a surveillance drone.
Data annotation is the process of adding metadata, labels, or tags to raw data, such as images, videos, text, or audio. This labeled data is then used to train AI and ML models to recognize patterns, make predictions, and take appropriate actions.
The quality and accuracy of the data annotation process directly impact the performance and reliability of the resulting AI system. Why data annotation is important should be obvious—it’s the difference between AI performing brain surgery and accidentally mistaking your dog for a Roomba. Poor annotations? Biased, error-ridden, and frankly embarrassing results.
The typical data annotation for AI workflow involves the following steps:
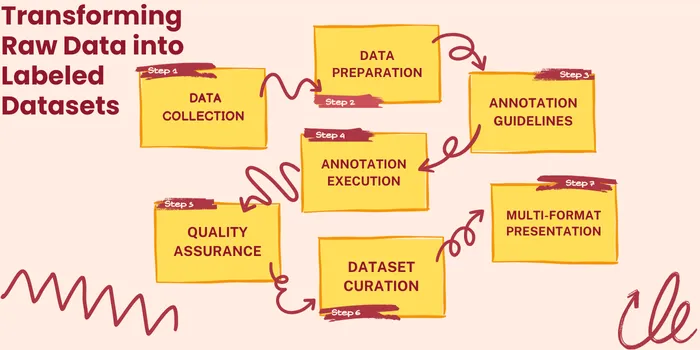
The resulting annotated dataset serves as the foundation for AI model development, enabling the models to learn from accurately labeled examples and make reliable predictions in real-world applications.
Let’s not kid ourselves. Without high-quality data annotation for AI, even the most advanced algorithms are just glorified toddlers trying to read War and Peace. Annotation quality isn’t just important—it’s everything. Because when it’s bad, well…things go south fast.
Conversely, high-quality data annotation ensures that AI models are trained on reliable, unbiased data, enabling them to make accurate, trustworthy predictions that can be readily scaled and deployed in real-world applications.
Achieving high-quality data annotation for AI requires careful planning, execution, and ongoing optimization. Here are some critical factors to consider:
Think of annotation guidelines as your AI’s bedtime story—clear, consistent, and absolutely crucial for happy results. Whether you’re labeling images or creating metadata for videos, guidelines should be laid out:
Take image annotation, for instance. Your guidelines might define:
Because without clear instructions? Chaos. And chaos doesn’t train models.
Here’s the thing: not everyone has the time (or patience) to get annotation right. That’s where agencies like LexiConn come in. They don’t just annotate your data—they create an ecosystem:
With LexiConn, you’re not just outsourcing—you’re leveling up. They’ll handle the end-to-end process so your AI models get the high-quality annotations they deserve.
Training AI isn’t just about throwing data at it and hoping for the best. If your AI training datasets don’t reflect the messy, chaotic, beautifully diverse world we live in, your model will fail faster than a bad blind date.
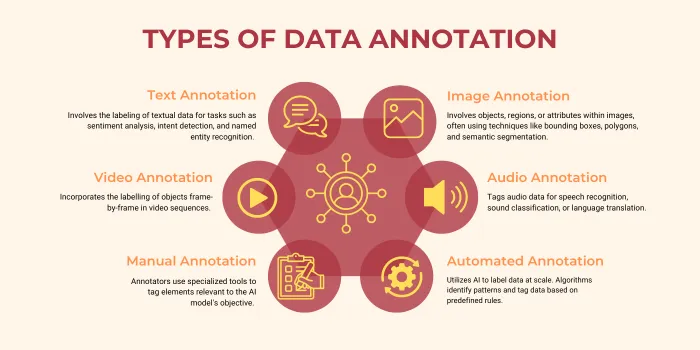
Here’s the deal: your annotated data needs to mirror everyone your AI will encounter—across demographics, geographic locations, environmental conditions, and all those quirks that make the real world real. Anything less, and you end up with a model that aces its training but panics the moment it steps into unfamiliar territory. Think of it as the AI equivalent of being great at karaoke and terrible at small talk.
As the demand for labeled data skyrockets, you need a workflow that can scale faster than your Netflix backlog.
A truly scalable machine learning data preparation process combines:
But scaling isn’t just about size—it’s about quality. Without effective workflow management and airtight quality assurance, your data could spiral into chaos faster than a group chat during the wedding season.
When it comes to data labeling services, accuracy is everything. A single mislabeled image, a stray annotation, or an inconsistent tag can throw your entire AI model into disarray. (And no one wants an AI making decisions like it’s half-asleep.)
High-quality annotations require ruthless attention to detail:
Agencies like LexiConn audit, cross-check and fine-tune every annotation like their reputation depends on it—because it does. With them, your AI gets data that’s as accurate as it is consistent.
Data annotation for AI is not a “set it and forget it” situation. It’s more like maintaining a relationship: constant attention, regular check-ins, and the occasional reality check when things start to drift.
Annotation isn’t a one-time fling; it’s a long-term commitment. As your target domain evolves or shiny new data sources come into play, your annotation guidelines and workflows need a refresh. Otherwise, you’re feeding yesterday’s leftovers to a model that needs fresh ingredients to stay sharp.
And let’s not forget machine learning data preparation doesn’t stop at labeling. Continuous performance monitoring of the AI models trained on your AI training datasets provides valuable insights for tweaking the annotation process. Think of it as feedback—except instead of a passive-aggressive “seen” text, you get actionable ways to boost your model’s real-world performance.
Data annotation for AI is a critical enabler for the successful deployment of AI and ML across a wide range of industries. Here are some examples of how data annotation supports key use cases:
In the healthcare sector, data annotation for AI plays a crucial role in the development of AI-powered medical imaging analysis tools, disease diagnosis systems, and personalized treatment plans. By accurately labeling medical scans, pathology samples, and clinical records, healthcare organizations can train AI models to detect and classify various medical conditions with high accuracy, helping healthcare providers make more informed decisions and deliver better patient outcomes.
The autonomous vehicle industry relies heavily on data annotation to train AI models for perception, planning, and decision-making tasks. Annotating sensor data, such as camera footage, LiDAR point clouds, and radar signals, enables self-driving car algorithms to accurately identify and track objects, pedestrians, traffic signals, and other relevant elements in the driving environment.
In the retail and e-commerce sectors, data annotation supports a wide range of AI applications, from product categorization and recommendation systems to automated inventory management and customer service chatbots. By annotating product images, customer reviews, and sales data, retailers can train AI models to deliver personalized shopping experiences, optimize supply chains, and enhance overall business operations.
Within the financial services industry, data annotation is crucial for developing AI-powered fraud detection, credit risk assessment, and portfolio management systems. By annotating financial transactions, credit reports, and market data, financial institutions can train AI models to identify suspicious activities, predict customer behavior, and optimize investment strategies.
Data annotation is the foundation upon which successful AI and machine learning models are built. By transforming raw data into accurately labeled datasets, data annotation enables AI systems to learn from reliable information, make precise predictions, and deliver superior performance in real-world applications.
As the global demand for AI continues to grow, the importance of high-quality data annotation will only increase. Organizations that invest in robust, scalable data annotation processes will be well-positioned to unlock the full potential of AI, driving innovation, efficiency, and competitive advantage across a wide range of industries.
Good annotation isn’t a luxury; it’s a lifeline. From avoiding bias to enabling scalability, data annotation for AI is the backbone of every successful model. Agencies like LexiConn ensure every frame of your image and video annotation, every guideline, and every pixel contributes to a smarter, more reliable AI future.
Because when it comes to AI, your model is only as good as the data it learns from. And trust me, it deserves better than “good enough.”
Book a free consultation call today!



I have read and accept the Privacy Policy
Read More